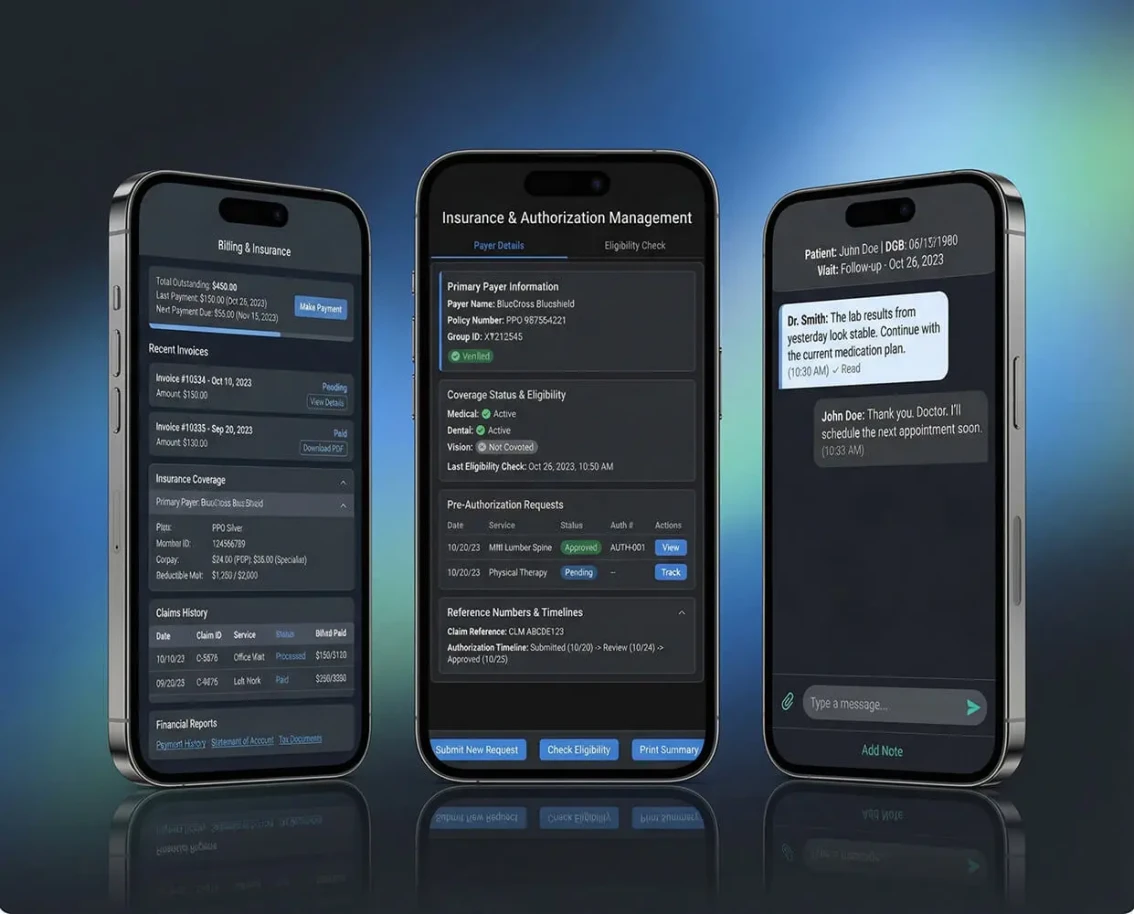
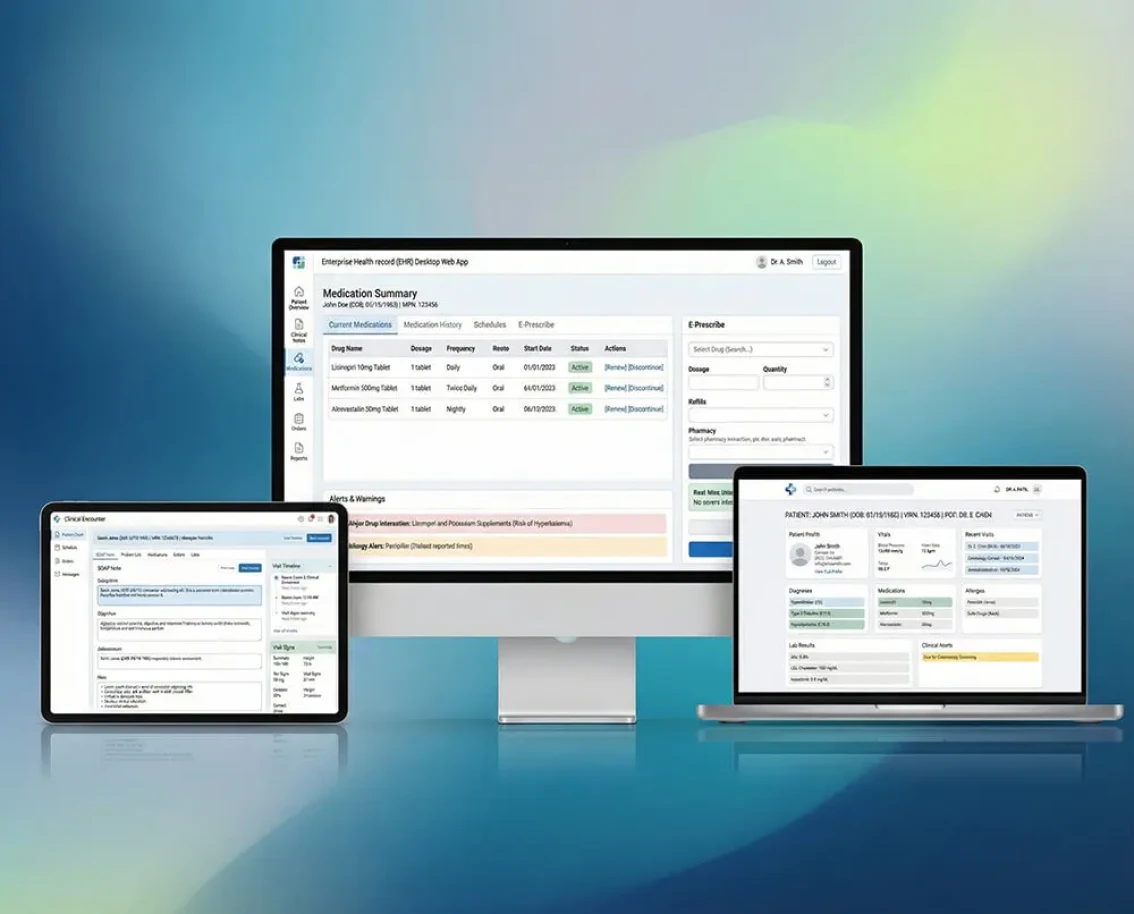
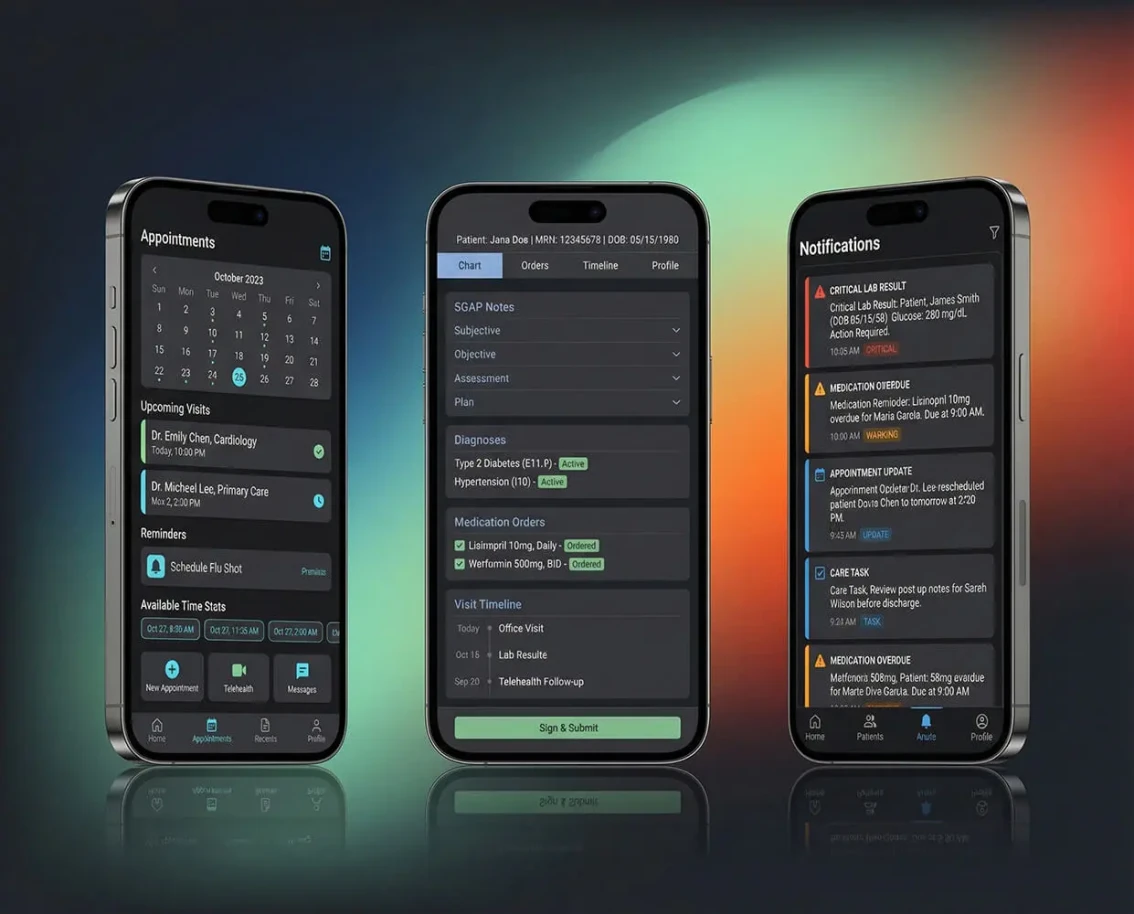
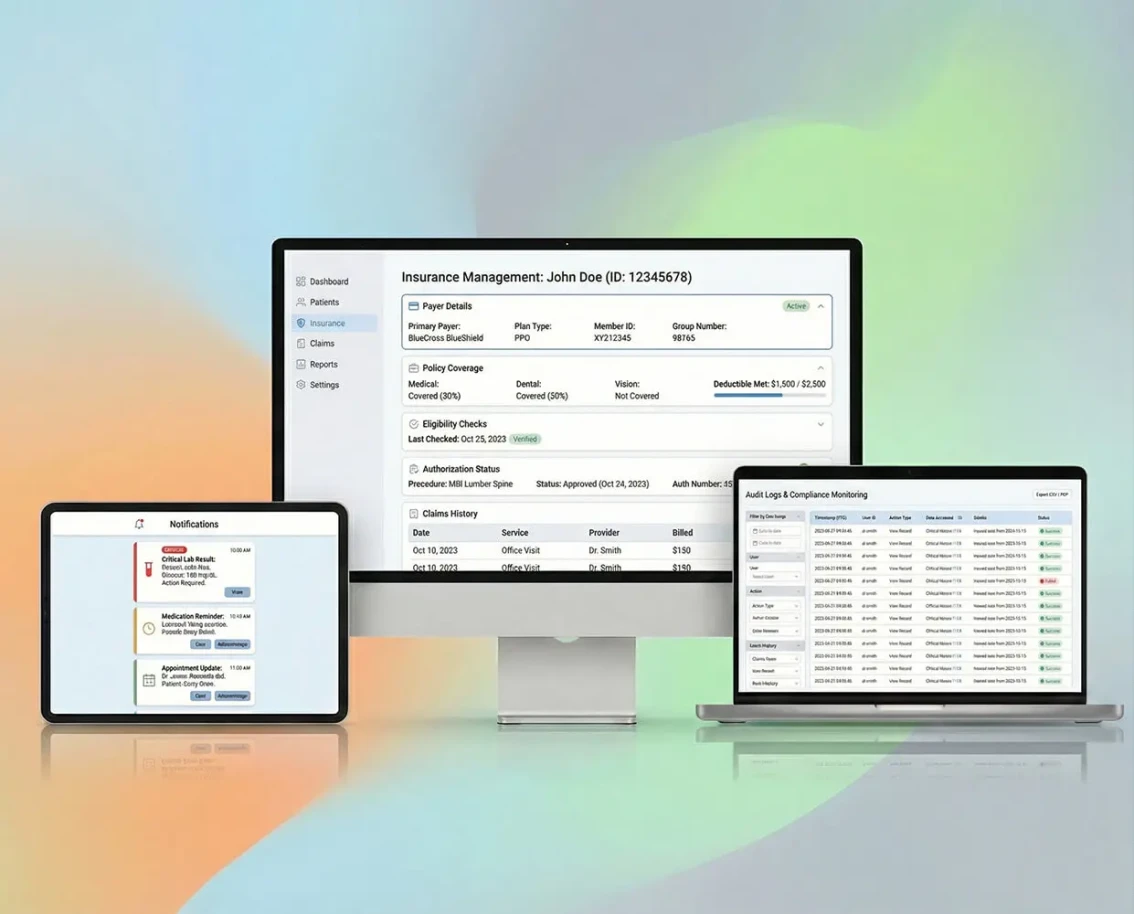
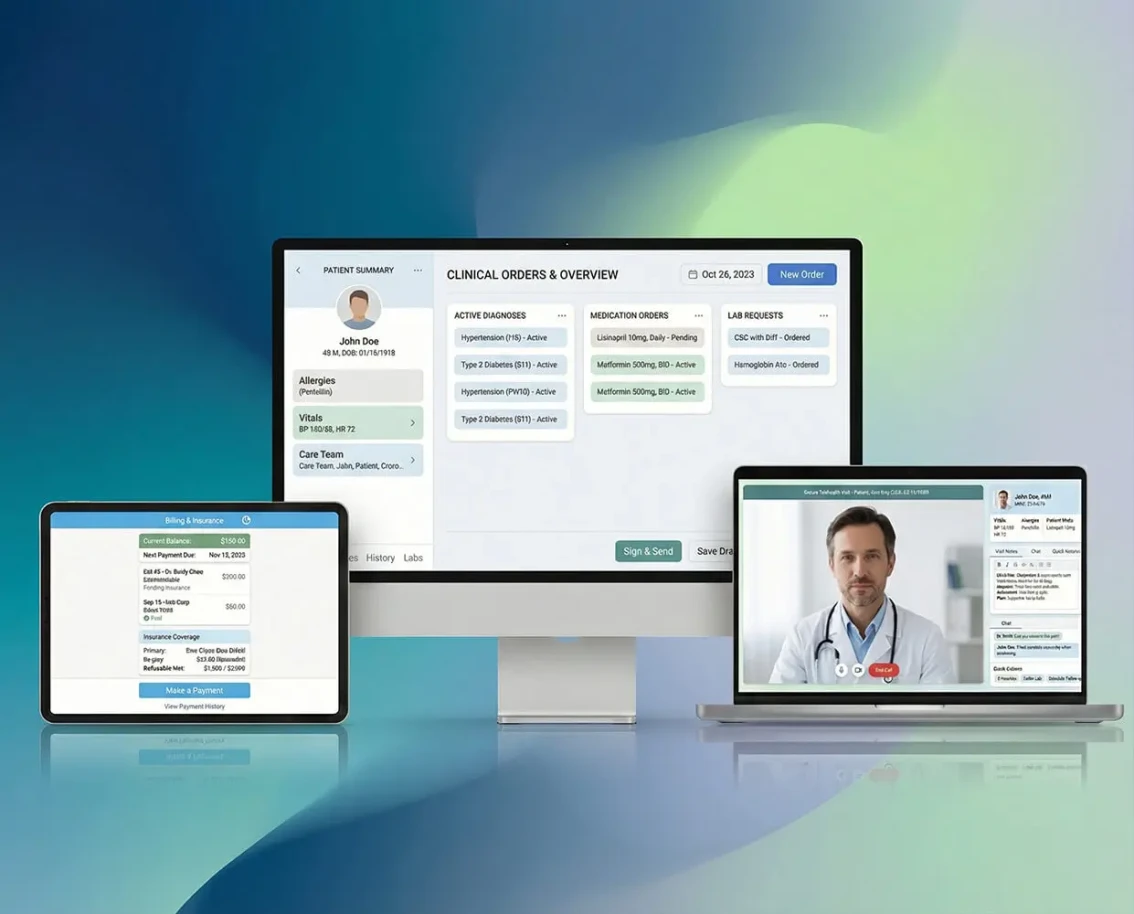
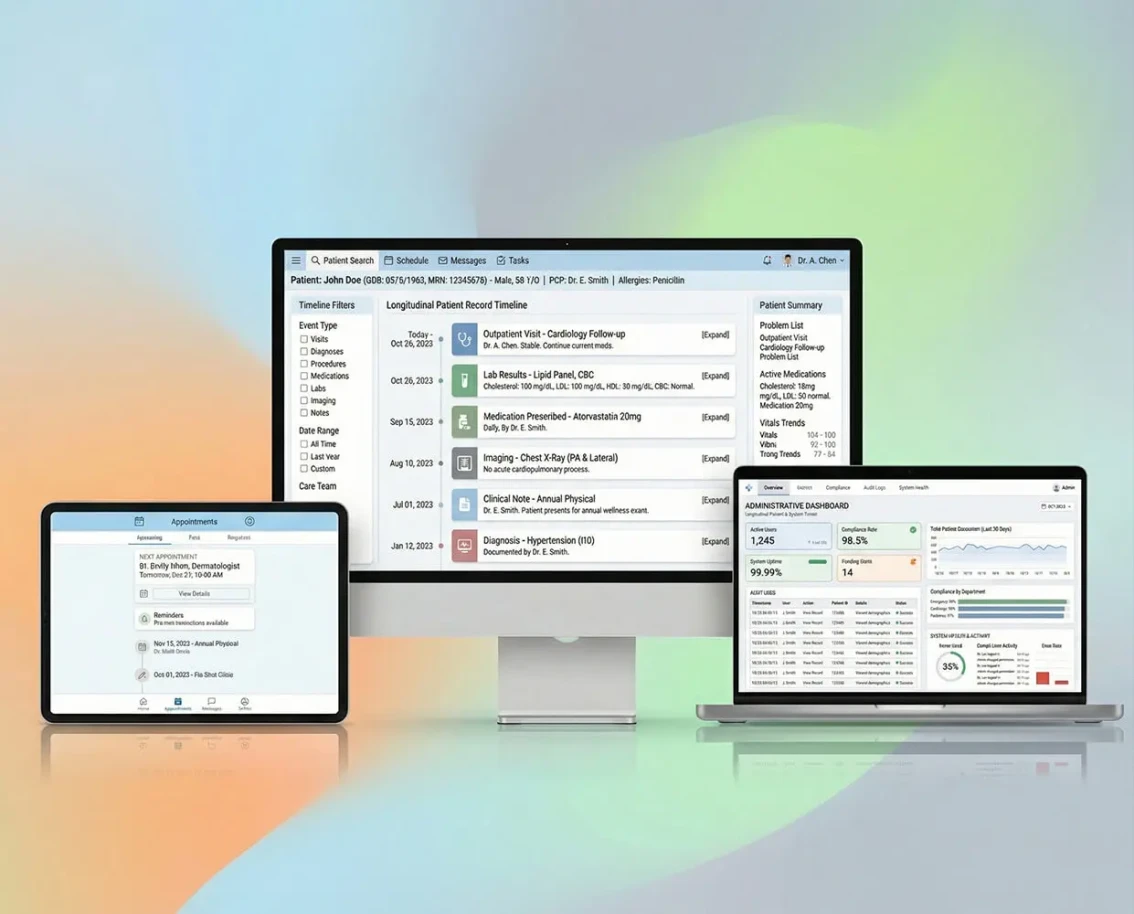
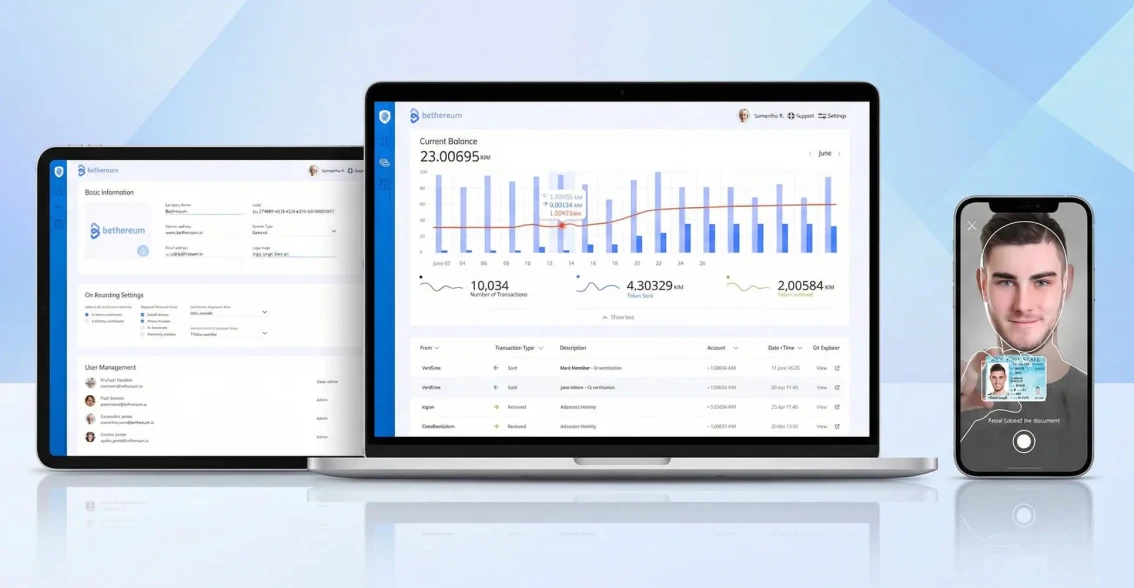
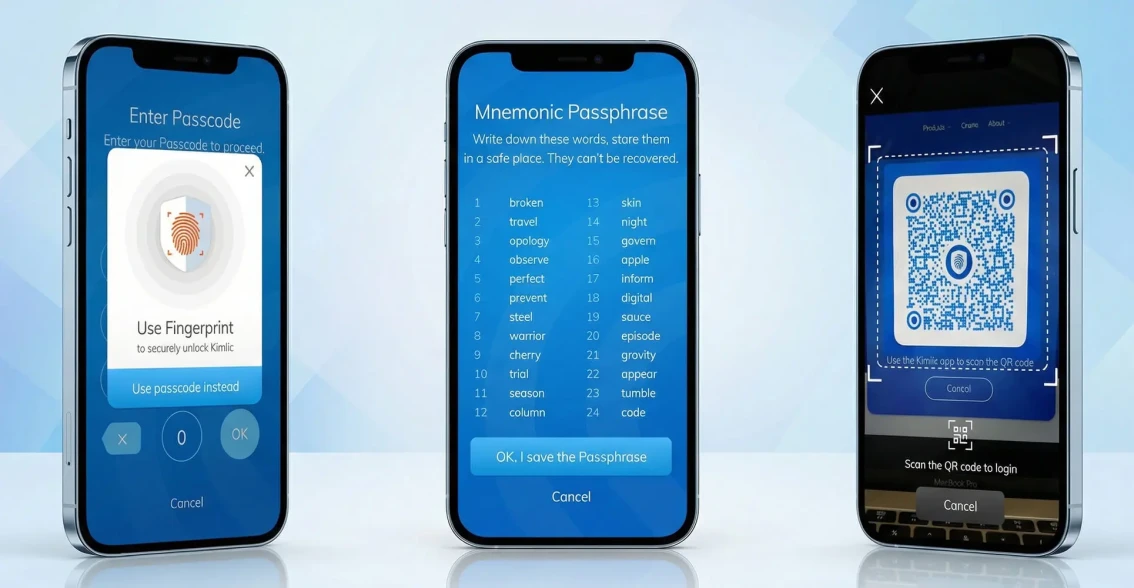
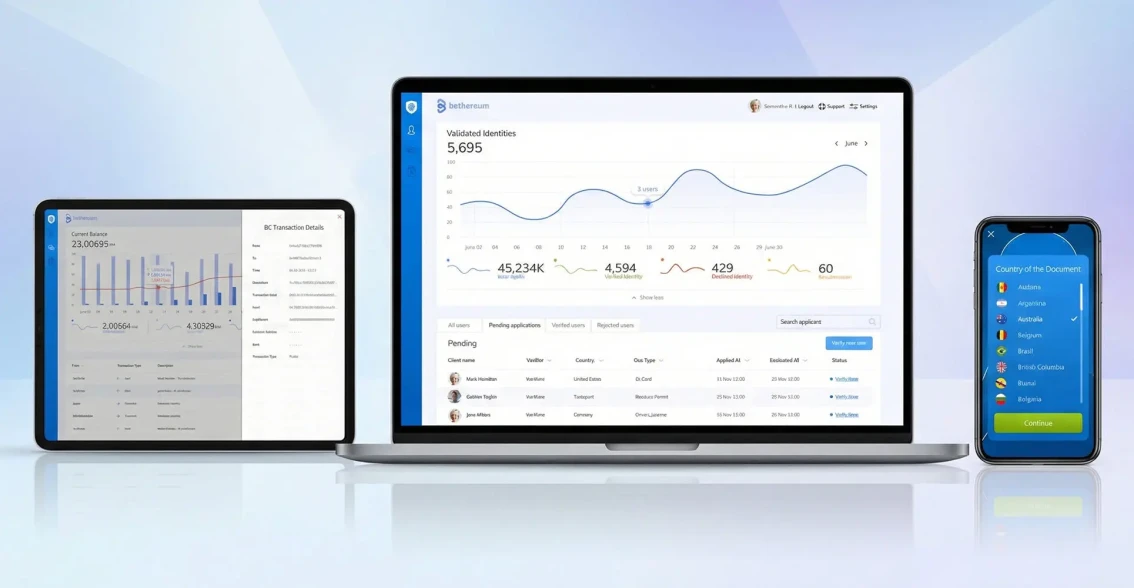
AI development is the process of building software that learns from data, reasons about problems and takes actions traditionally requiring human judgment. Unlike traditional software that follows explicit rules, AI systems use machine learning models, large language models (LLMs) and neural networks to handle unstructured inputs - natural language, images, audio, time-series patterns. Common production AI project types include conversational AI agents, RAG (retrieval-augmented generation) systems, custom model training, computer vision pipelines, NLP extraction and multi-agent orchestration. The
Stanford HAI AI Index 2025 tracks record investment in generative AI, and
McKinsey State of AI 2025 reports 78% of organizations using AI in at least one function. Gartner forecasts
global genAI spending of $644 billion in 2025. This page is for founders, CTOs and data leaders at FinTech, healthcare, Web3 and enterprise companies evaluating AI development partners - with an honest view of what ships, what fails and how our
2026 AI cost research prices the hidden layers buyers miss at RFP time.
Authoritative citations
5 sources
-
IDC
Worldwide enterprise AI spending forecast through 2027 by industry vertical
 idc.com
2024
idc.com
2024
-
Stanford HAI AI Index
AI Index 2025 tracks training compute, model performance, investment and adoption metrics across the global AI industry
 hai.stanford.edu
2025
hai.stanford.edu
2025
-
McKinsey and Company
State of AI surveys global adoption, ROI realisation and risk-management practices across enterprise
 mckinsey.com
2025
mckinsey.com
2025
-
Gartner
Worldwide GenAI spending forecast tracks platform, services and infrastructure investment
 gartner.com
2025
gartner.com
2025
-
NIST
AI Risk Management Framework provides governance, mapping, measurement and management functions for trustworthy AI systems
 nist.gov
2024
nist.gov
2024
What we do not do:
- AI features where deterministic rules engines would be cheaper and more reliable
- Demos or proofs of concept without a production deployment plan
- Projects expecting fixed quotes without a paid discovery sprint
- Use cases where data privacy requirements rule out cloud LLM APIs and budget cannot cover self-hosted GPU infrastructure