Guide to the Web3 Stack for Developers in 2026
Explore the Web3 stack in 2026 with a practical guide to blockchain development, dApp architecture, smart contracts, wallets, RPC infrastructure, indexing, decentralized storage and production readiness. Learn how to choose the right Web3 tech stack for scalable, reliable and secure applications.

Building a Production-Ready Web3 Stack in 2026 6
This guide explains how modern Web3 teams structure the stack for real production use, not just demos. The core themes are architectural boundaries, six-layer stack design, protocol rules, read/write separation and the infrastructure decisions that determine whether a Web3 product stays reliable under real network conditions.
- Trust Boundary Shift The core architectural change in Web3 is that trust no longer sits only in the backend. Wallets, contracts and consensus now shape identity, writes and user-visible system behavior, so teams need to design for signing, finality and shared state from the start.
- The Six-Layer Stack A production-ready Web3 stack is easier to reason about when it is split into layers: interface, compute, contracts, runtime, data and tooling. This layered model helps teams assign responsibilities clearly and avoid pushing the wrong logic into the wrong part of the system.
- Smart Contract Guardrails Smart contracts should enforce shared, verifiable rules such as ownership, permissions and critical state transitions. They work best when they stay focused on protocol behavior instead of absorbing generic application logic that belongs elsewhere.
- 2026 Development Environments Scalable Web3 systems must separate read paths from write paths. Reads should be optimized for indexed, query-ready data, while writes must handle signing, nonce management, gas estimation and confirmation uncertainty without degrading the product experience.
- Read/Write Separation A Web3 stack becomes production-ready only when it can tolerate RPC provider failures, maintain reliable read models, support storage and indexing choices deliberately and trace user-visible behavior across the whole system. Infrastructure is part of product quality, not a layer to postpone until after launch.
- Final Standard for Production Readiness Mature Web3 teams design every layer with accountable ownership, explicit operating targets and known failure patterns. That discipline is what allows them to scale safely, ship faster and keep the system understandable under real network pressure.
Introduction: Why Web3 dApp design matters for modern product teams
Web3 products do not fail because teams lack tools. They fail when the wrong responsibilities are distributed across the wrong layers and the signing flow is treated like an afterthought.
A modern Web3 product is not defined by smart contracts alone. It is shaped by a chain of architectural decisions about trust, execution, identity, data access and operational control. In 2026, the key question is not whether Web3 belongs in a serious product roadmap. The real question is how to use Web3 components where they add clear value without making delivery slower, riskier and harder to operate.
For product and engineering teams, Web3 changes more than the technology stack. It changes the system boundary. Ownership, access, asset movement and transaction integrity can no longer be treated as ordinary application features. Once wallets, signatures, public state and on-chain execution become part of the product, architecture decisions carry direct consequences for security, usability and scale.
What this guide will help you do
- Separate product logic from trust-critical execution paths
- Choose a Web3 stack that works in production, not only in demos
- Avoid unnecessary complexity, delivery drag and architectural rework
That is why a production-ready roadmap starts with a simple discipline: decide what must live on-chain and what should remain off-chain. Some functions require verifiable execution and shared state. Others are better handled by conventional application services, indexed databases, background workers and API layers. Teams that get this boundary right build faster, reduce complexity and preserve the guarantees that make Web3 useful in the first place.
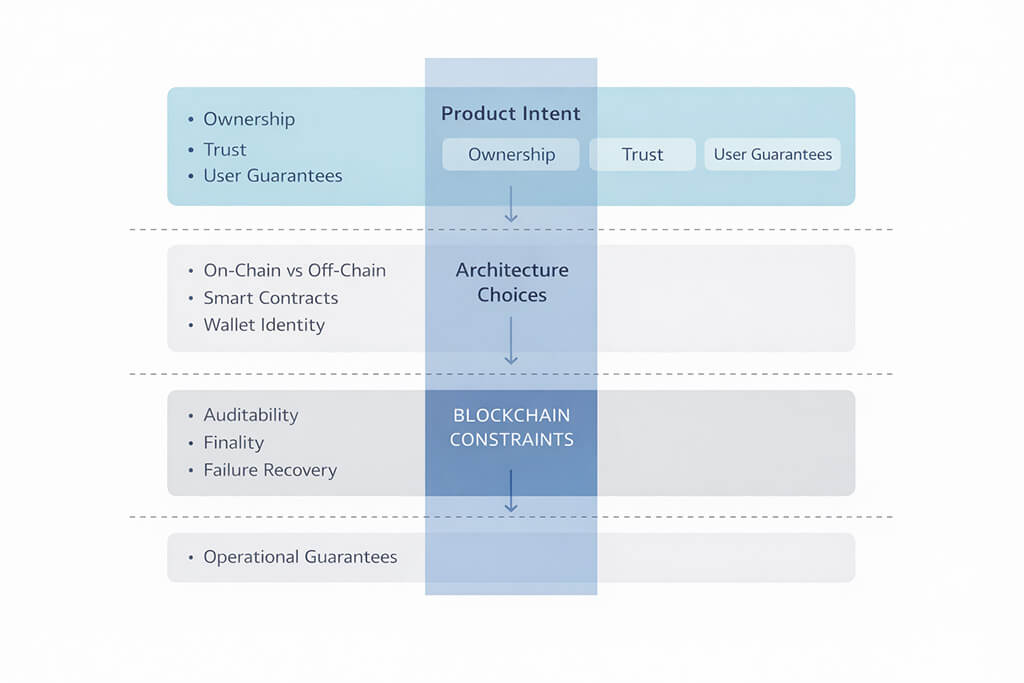
The diagram above frames that decision path. Product intent sits at the top: what users need to trust, own or verify. Architecture choices sit in the middle: what belongs on-chain, what belongs off-chain and how wallets, contracts and services interact. Under that sits the reality every team has to design around: blockchain constraints such as finality, auditability, failure recovery and operational guarantees under load.
ARCHITECT’S NOTE: A Web3 product succeeds or fails at the architecture boundary
After 23 years in software architecture, one pattern remains constant: systems break where responsibilities are poorly assigned. Web3 makes that reality harder, not easier. The contract is only one part of the system. The real engineering challenge sits at the boundary between wallet flows, trust assumptions, on-chain execution, off-chain services, indexed data and operational control. If that boundary is designed poorly, the team will feel it everywhere: in delivery speed, reliability, support load, security review and future change cost.
Many teams focus too early on frameworks, chains and development tooling. Those choices matter, but they should follow one prior decision: which rules must remain shared and verifiable, and which parts of the product need speed, flexibility and operational recovery. When that line is drawn clearly, the stack becomes easier to scale and much easier to maintain.
A Web3 stack is therefore not one tool and not one framework. It is a modular system that spans the user-facing application, backend services, smart contract logic, wallet flows, RPC access, indexing and monitoring. This guide breaks those layers down one by one so teams can choose the right stack for real production systems and avoid turning Web3 adoption into an open-ended research project.
A Simplified Definition of the Web3 Structure
A Web3 product is not a smart contract with a frontend attached. It is a layered system that separates user intent, identity, application logic, on-chain execution and product-ready data access. If you want to understand how a Web3 stack works in production, start with the way those layers interact.
At a high level, the structure is simple. The interface captures what the user wants to do. The wallet proves identity and authorizes actions. Backend services apply product rules, coordinate workflows and protect infrastructure. Smart contracts execute the shared rules that must be verified on-chain. Around all of that, the data layer turns raw blockchain activity into usable reads for dashboards, search, notifications and reporting.
This model matters because it helps engineering teams separate signing, application coordination, on-chain execution and product-ready data access. Once those boundaries are clear, architecture decisions become easier to evaluate and much harder to get wrong.
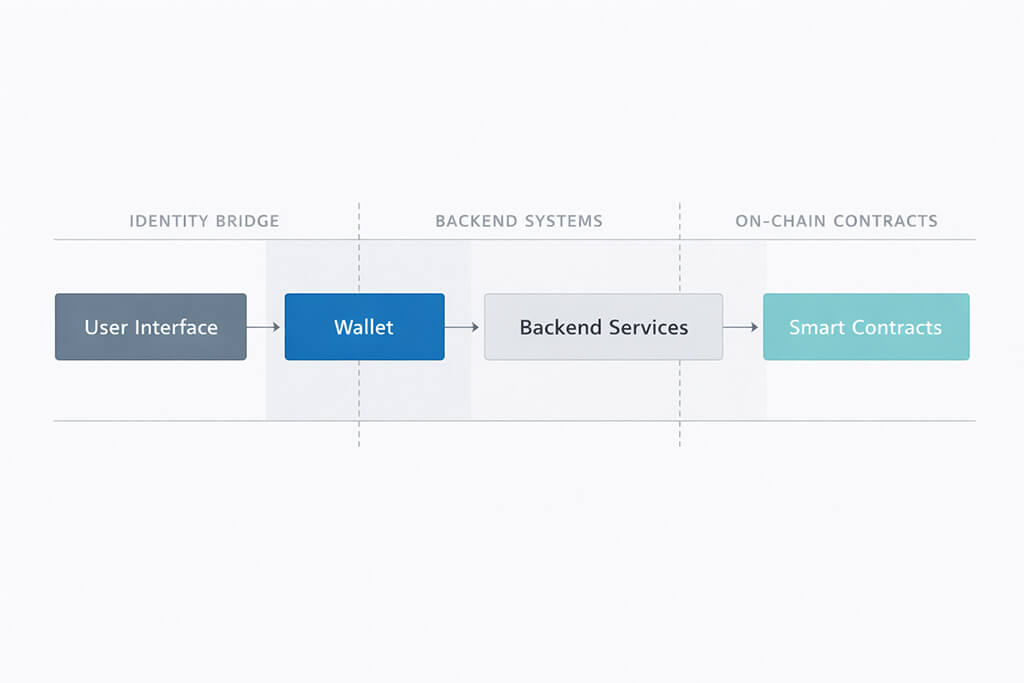
The diagram above should be read from left to right. The user begins in the interface. The wallet handles identity and authorization. Backend services handle coordination, policy enforcement, caching and infrastructure protection. Smart contracts handle the parts of the system that require shared state, deterministic execution and on-chain verification.
The five working layers of a production Web3 system
1. Interface layer. This is where users review intent and initiate actions. A good interface makes ownership, approvals, transaction consequences and confirmation steps easy to understand. In Web3, clarity at the UI layer is not just a design concern. It directly affects trust and conversion.
2. Wallet layer. The wallet connects identity, signing authority and asset control. This is the point where the user authorizes actions, not just where they log in. That is why wallet behavior has architectural importance, not only UX importance.
3. Application layer. Backend services and APIs sit here. This layer enforces product policy, manages workflow orchestration, protects infrastructure, handles caching and supports integrations that do not belong on-chain. It is also where teams preserve flexibility as product requirements evolve.
4. Contract layer. Smart contracts define the rules that must be shared, verifiable and executed on-chain. This is the right place for critical state transitions, asset logic and protocol behavior that cannot depend on a private backend. It is not the right place for every product feature.
5. Data layer. Raw blockchain events are not the same as a product-ready read model. Most real products need indexing, transformation and queryable datasets to support search, notifications, analytics, dashboards and operational reporting. This layer turns blockchain activity into an application people can actually use at scale.
Seen this way, the Web3 structure is a practical system of boundaries. The interface captures intent. The wallet authorizes it. The application layer coordinates it. The contract layer executes what must be verifiable. The data layer makes the result usable for the product.
What a well-designed Web3 stack gives you
A well-designed Web3 stack gives the product clearer ownership boundaries, stronger execution guarantees and more room to evolve without constant architectural rework.
1. Clearer ownership and user portability
A wallet-based identity model gives users a more consistent way to access products across environments and applications. It reduces dependence on passwords, reset flows and centralized account recovery, while giving teams a cleaner model for ownership, permissions and user-controlled actions. When supported standards are chosen carefully, portability becomes a product advantage rather than a technical promise that breaks in practice.
That matters early in architecture planning. Teams can define which assets, permissions and account behaviors should travel with the user and which should remain inside application-specific services. This creates a clearer scope before development begins and reduces confusion later in onboarding, support and expansion.
2. Shared rules and verifiable execution
Smart contracts are valuable when product rules need to be enforced consistently by the system itself, not by private application logic alone. This is especially useful for asset issuance, permissions, settlement flows and other state changes that require predictable execution. When these rules live on-chain, teams gain a stronger foundation for auditability, traceability and multi-party trust.
That benefit only becomes real when the contract layer is treated as engineering infrastructure, not as a shortcut. Assumptions need to be documented, edge cases need to be tested and security review needs to happen before the contract becomes part of production behavior. A well-designed stack makes those responsibilities explicit and helps the rest of the application remain stable around them.
3. Composability and faster iteration
One of the strongest advantages of Web3 is composability. Products can connect to existing protocols, token standards and ecosystem services instead of building every primitive from scratch. That can accelerate roadmap execution, especially when the team adopts dependencies intentionally and keeps interfaces stable across releases.
Composability does not remove complexity. It changes the kind of complexity you manage. Integration risk, protocol assumptions and external dependencies all need to be evaluated carefully. But when the stack is designed with those realities in mind, teams can move faster, reuse proven building blocks and adapt more easily as requirements evolve.
These gains matter because they make the product easier to scale, review and evolve over time without rebuilding core assumptions at each stage.

What changes compared to a typical Web2 blueprint
The biggest architectural shift is where trust lives. In a typical Web2 system, the application backend is the main authority. It controls state, approves writes and defines the source of truth. In a Web3 system, that authority is split across wallets, smart contracts and the consensus rules of the chain. Once that shift happens, identity, writes, latency and recovery all have to be designed differently.
This is why Web3 should not be approached as a Web2 stack with a blockchain feature added on top. The trust boundary moves outward. Signing becomes part of the user flow. Finality becomes part of system behavior. Infrastructure choices such as chain selection, wallet support and EVM compatibility affect product design much earlier than they do in a conventional backend-led architecture.
Architectural Shift: Web2 vs. Web3
| Core concept | Typical Web2 blueprint | Web3 stack (2026) |
|---|---|---|
| Trust boundary | The backend server owns the source of truth. | Wallets, contracts and consensus define the trust boundary. |
| Write operations | Writes are internal database updates with near-instant confirmation. | Writes require signing, fees and a finality window before they can be treated as complete. |
| User identity | Identity is managed by the application through accounts and credentials. | Identity is anchored in the wallet, with stronger ownership portability across products and environments. |
The table above captures the core shift. In Web2, the application owns control and can hide most infrastructure complexity from the user. In Web3, some of that complexity moves into the product experience itself. Wallet connection, transaction signing and confirmation states become first-class UX elements because they are part of how trust is established and verified.
Read paths also change. In a traditional Web2 system, product reads usually come straight from the application database. In Web3, raw chain data is rarely optimized for responsive product queries. Most production systems need indexing, caching or a dedicated read model to support dashboards, search, notifications and other iterative user flows.
Write paths become more sensitive as well. Every write can carry cost, signing friction and variable confirmation time. The chain may be fast, but the user experience still depends on gas conditions, wallet behavior and the finality model of the network. That is why seemingly small interface decisions can have a large downstream effect on reliability, support load and conversion.
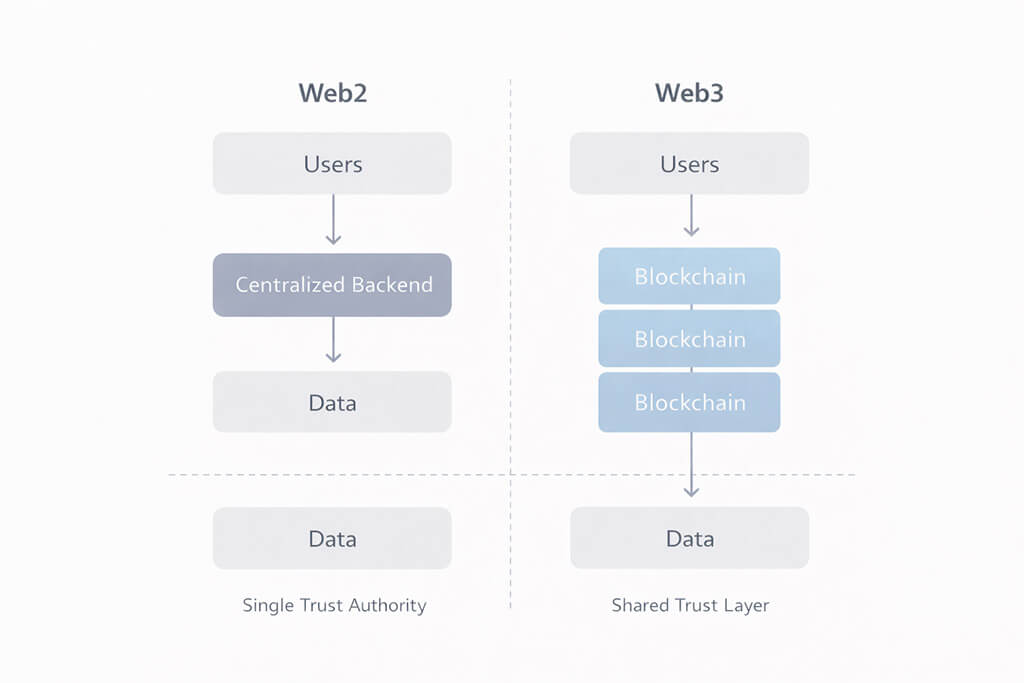
This comparison reinforces the same point in simpler form. Web2 routes users through a centralized backend that governs data and system behavior. Web3 introduces a shared trust layer between the user and the data model. That shift is what makes Web3 architecture fundamentally different and why teams need to design for trust, signing and finality from the start.

The 6 Layers of a Production Web3 Stack
A Web3 stack is not just a collection of tools. It is a layered system that separates user interaction, application coordination, on-chain execution, runtime behavior, data access and developer workflow. Teams that understand those boundaries make better decisions about where logic should live and how the product should behave under real production conditions.
That separation matters because Web3 systems do not fail for the same reasons as conventional applications. User intent may begin in the interface, but execution, authorization, data access and runtime behavior are distributed across multiple layers. If responsibilities blur across those layers, the product becomes harder to ship, harder to review and more expensive to evolve.
The six-layer model below provides a practical way to think about the stack. Read it as a set of engineering boundaries, not just a vertical sequence of technologies. The upper layers are closer to user experience and coordination. The middle layers govern execution and protocol rules. The lower layers support runtime behavior, read models and the development workflow around the system.
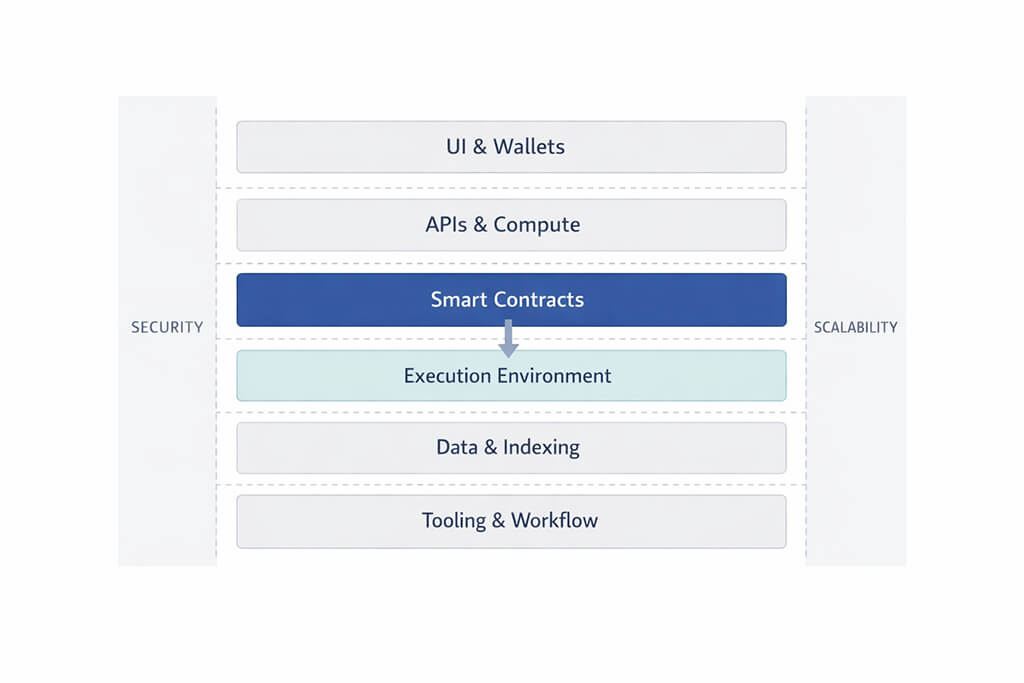
This model is useful because it helps teams decide what belongs in the interface, what belongs in application services, what must be enforced on-chain, what depends on network runtime behavior and what must be transformed into product-ready data before users ever see it.
Layer 1: Frontend, Wallets, and User Interaction
This is the product-facing layer of the stack. It captures user intent, presents transaction consequences and guides people through wallet connection, approvals, signing and confirmation. In Web3, these interactions are not cosmetic details. They are part of the trust model and have a direct effect on conversion, support load and perceived reliability.
A strong interface makes ownership, permissions, fees and timing understandable before the user commits to an action. It also communicates what is happening during signing, submission and confirmation instead of treating the blockchain as an invisible backend. That matters because latency, rejections and finality windows shape user behavior in ways that typical Web2 flows do not.
What belongs here is clear presentation of intent, wallet connection, approval flows, transaction status and user-readable consequences. What does not belong here is hidden protocol logic or business policy that should be enforced elsewhere. The interface should explain the system, not compensate for architectural ambiguity.
Layer 2: Application Compute, APIs, and Orchestration
This layer sits between the user-facing product and the protocol-facing parts of the system. It validates requests, coordinates workflows, manages retries, enforces product policies that do not belong on-chain and protects infrastructure behind stable APIs. In many production systems, this is the layer that turns a collection of blockchain interactions into a usable application experience.
Not every important rule belongs inside a contract. Many flows still depend on orchestration, rate limits, automation, queues, integrations and service-level controls that are easier to manage in application infrastructure. Good API boundaries reduce coupling between the interface and the rest of the system while keeping the product flexible as requirements evolve.
This layer matters because it absorbs operational complexity without hiding trust-critical behavior from the user. It is where teams keep product coordination practical, especially when multiple services, wallets or external systems need to work together reliably.
Layer 3: Smart Contracts and Protocol Rules
This is the layer where shared rules are enforced through verifiable execution. Smart contracts define how critical state changes happen, how assets move, how permissions are checked and how protocol behavior is recorded on-chain. If a rule must be shared, reviewable and enforced independently of a private backend, this is usually where it belongs.
In production, the contract layer should stay focused on what genuinely benefits from on-chain enforcement. Asset transfer logic, access control, governance rules and protocol-level permissions are good candidates. Generic application behavior, private workflow coordination and product-specific convenience logic often are not.
This layer also defines the event stream that downstream systems rely on. Good event design makes indexing, monitoring and analytics far easier. Poor event design pushes complexity outward into every integration and every read path the product depends on.
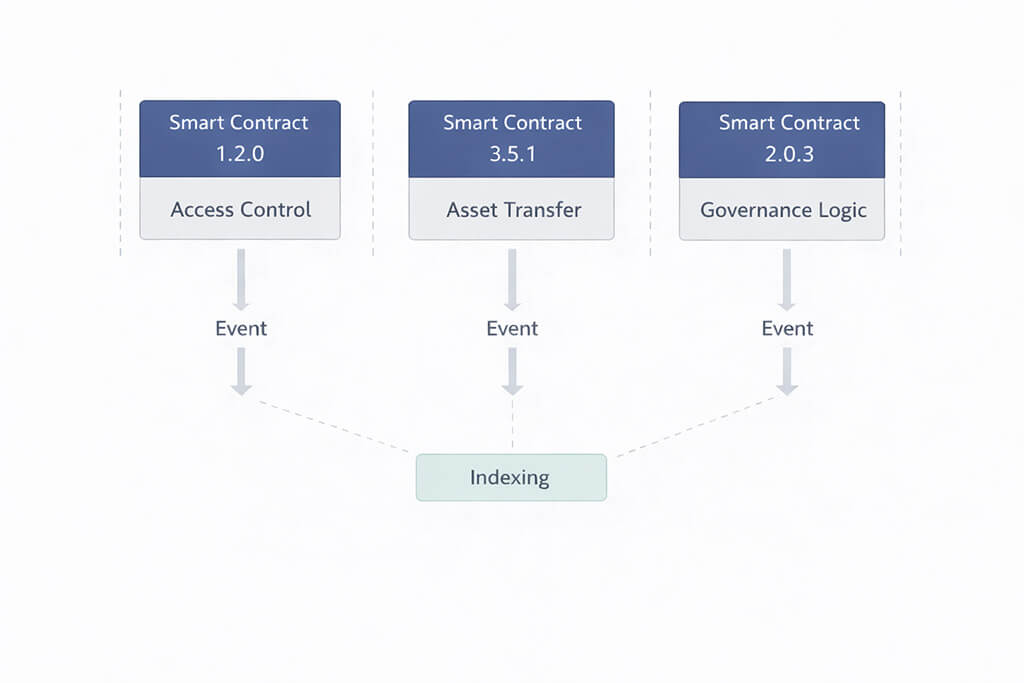
This supporting diagram highlights an important production pattern: many application reads begin with contract events, not with direct chain reads. Contracts enforce protocol rules, emit event data and feed the indexing layer that later powers dashboards, histories, alerts and operational views.
Layer 4: Execution Environment and Network Runtime
This layer defines where contract logic actually runs. It includes the chain runtime, the network environment and the execution semantics that shape fees, propagation, confirmation and finality. For EVM-based systems, that may include Ethereum-compatible mainnets, rollups, devnets, testnets and local environments. For other ecosystems, the same principle applies through their own runtime models.
Choices here affect more than deployment. They determine how gas is calculated, how fast transactions propagate, how predictable confirmation timing is and how closely non-production environments resemble real network behavior. A stack that behaves one way in test environments and another way in production quickly becomes expensive to stabilize.
This is why environment parity matters. Teams need realistic assumptions about runtime behavior before they ship. A contract may be correct and still fail as part of the product if network behavior, fee conditions or execution timing were simplified too aggressively during development.
Layer 5: Data, Indexing, and Queryable Read Models
Raw blockchain data is rarely shaped for product use. Modern Web3 applications need searchable histories, fast queries, filtered views, dashboards, alerts and operational reporting. That means most serious products need a dedicated read path that transforms raw chain activity into structured, query-ready data.
In practice, this layer converts blocks and event logs into indexed datasets that the product can query efficiently. It is what makes real-time dashboards, portfolio screens, search flows, notifications and audit-friendly histories possible without forcing the interface to read directly from raw chain state on every request.
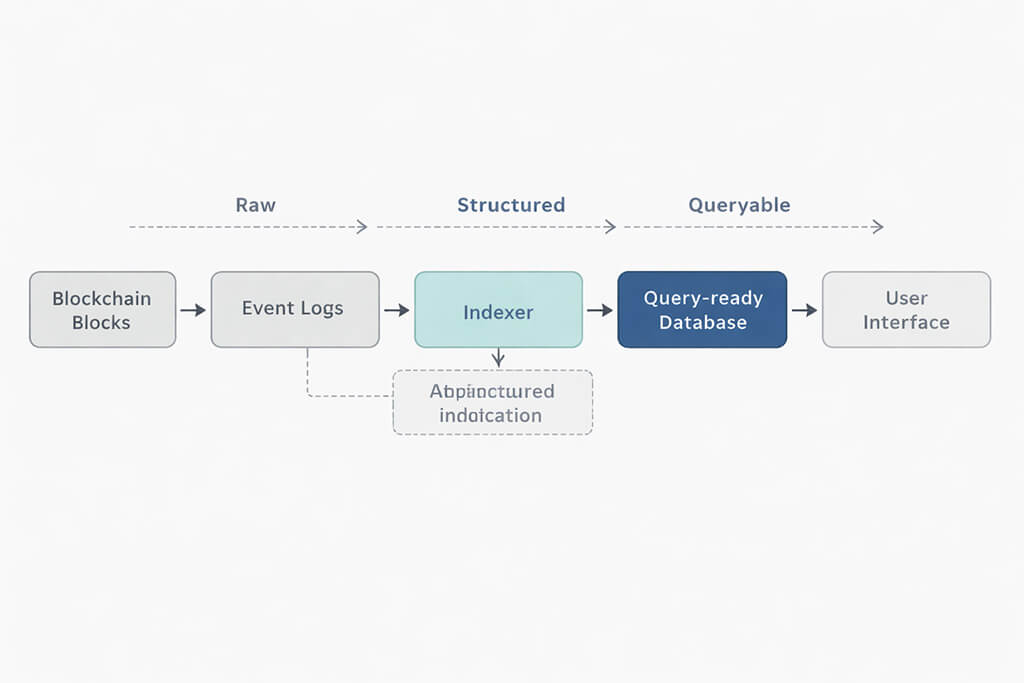
The indexing pipeline above shows the basic flow from raw chain output to structured product data. Blocks and logs provide the source material. The indexer normalizes and enriches it. A query-ready database makes it usable for the application. The interface then consumes a read model designed for people, not for protocol internals.
This layer also carries real operational weight. Teams need to manage refresh lag, consistency guarantees, telemetry reconciliation and alerting around broken or delayed pipelines. Indexing decisions are often a major driver of both system complexity and infrastructure cost, so observability here should be treated as a core deliverable, not as a later optimization.

Layer 6: Languages, SDKs, and Integration Tooling
This is the workflow layer around the system. It includes the languages, frameworks, SDKs and integration choices teams use to build, test, deploy and maintain the stack. It does not define where contracts run. It defines how engineers work with the system consistently over time.
In many Web3 products, JavaScript and TypeScript dominate the interface and application layers because they fit naturally with web clients, service orchestration and integration-heavy backends. Python often appears in scripting, automation, analytics and operational tooling. Rust is valuable in ecosystems and services where performance, low-level control or protocol-specific tooling make it the better fit.
SDK choice matters because every ecosystem has its own signing conventions, encoding rules, transaction models and integration quirks. Frameworks such as Hardhat, Foundry, Truffle or ecosystem-specific SDKs can reduce uncertainty, but they also shape how teams test, deploy and debug the product. The goal is not to use the broadest toolchain possible. It is to choose the smallest and clearest tool surface that still supports the product’s requirements.
That principle matters for long-term maintainability. Every extra SDK, abstraction layer or chain-specific helper adds integration cost, upgrade risk and documentation burden. Teams that keep this layer disciplined usually move faster because they reduce operational noise and keep the stack understandable for future engineers.
Taken together, these six layers turn the Web3 stack from a vague collection of technologies into a practical system of boundaries. The interface captures intent. Application services coordinate behavior. Contracts enforce shared rules. The runtime determines how execution behaves. The data layer produces usable read models. Tooling supports how the team builds and evolves the product. Once those boundaries are clear, the rest of the architecture becomes much easier to reason about.
How to Choose a Web3 Stack by Product Type
There is no single best Web3 stack for every product. The right architecture depends on what the product is trying to optimize: trust, speed, portability, compliance, cost, read performance or ecosystem compatibility. Teams usually make better decisions when they start with product behavior and failure tolerance, not with a preferred chain, framework or wallet library. Once those constraints are clear, the stack becomes easier to shape around the product instead of around tooling preferences.
1. Wallet-connected consumer apps
For consumer-facing Web3 applications, the interface and wallet layer usually matter more than the contract layer at the start. Products in this category often depend on fast onboarding, low-friction signing flows, clear transaction feedback and stable read performance. Users will judge the product by responsiveness and clarity long before they evaluate protocol elegance.
In this case, the stack should prioritize wallet compatibility, low-friction transaction handling, strong indexing and responsive read models. Backend orchestration also matters because it helps coordinate retries, notifications, session continuity and product logic that should not live on-chain. The most common mistake here is overengineering the contract layer while underdesigning the read path and the user journey.
2. DeFi products and protocol interfaces
For DeFi systems, the contract layer and execution environment become much more critical. These products depend on shared rules, asset movement, deterministic execution and precise handling of state changes under adversarial conditions. Even when the interface is polished, the product ultimately succeeds or fails on protocol behavior, transaction handling and security review.
A good stack for this category should emphasize contract clarity, event design, runtime realism, threat modeling and clear separation between write paths and product reads. Indexing is still essential because dashboards, positions, histories and alerts depend on queryable data. The most common mistake here is to focus on UI and integrations while underestimating the cost of protocol-level complexity, runtime assumptions and adversarial failure modes.
3. NFT, media and digital asset platforms
Products centered on NFTs, collectibles, tickets or digital media usually depend on more than contract logic alone. They also depend heavily on metadata design, off-chain asset storage, retrieval performance and permanence choices. In these systems, the storage layer becomes a first-class architecture decision rather than an afterthought.
The right stack here often combines on-chain ownership and transfer logic with off-chain media storage, metadata handling and content delivery strategy. IPFS may be a good fit when distribution and retrieval matter most. Arweave can make more sense when long-term permanence is part of the product promise. The most common mistake is to define ownership correctly on-chain but leave metadata availability, pinning strategy and retrieval behavior operationally vague.
4. Read-heavy analytics and portfolio products
Some Web3 products are not write-heavy at all. Their real value comes from aggregating, interpreting and presenting blockchain activity in a fast and understandable way. Portfolio dashboards, analytics products, monitoring tools and reporting systems often fit this pattern. In these cases, the data and indexing layer becomes the real center of gravity.
The stack for a read-heavy product should prioritize ingestion reliability, query-ready databases, indexing freshness, filtering performance and observability of the read pipeline. Here, the product wins or loses on the quality, timeliness and usability of the read model rather than on contract complexity alone.
5. Enterprise and regulated Web3 platforms
Enterprise and regulated products usually need stronger control over environments, audit trails, permissions and operational predictability. They may still use public blockchain infrastructure, but they often require stricter release discipline, clearer separation of responsibilities and stronger evidence around how state changes, access controls and off-chain processes are managed.
For this category, the stack should emphasize explicit boundaries between protocol logic and application services, strong observability, environment parity, documented threat models and measured rollout processes. Teams should also decide early which parts of the product must remain publicly verifiable and which parts must remain operationally recoverable. The most common mistake is to copy a consumer-style Web3 stack into a context that actually demands tighter operational controls and clearer accountability.
What to evaluate before choosing the stack
- Trust model: What must be publicly verifiable and what can remain application-controlled?
- Read intensity: Will the product depend more on fast reads than on frequent writes?
- Write sensitivity: How much signing friction, confirmation delay and fee variance can the product tolerate?
- Storage needs: Does the product depend on permanence, caching or high-volume retrieval of off-chain assets?
- Operational pressure: How important are observability, rollout discipline and failure isolation?
- Ecosystem fit: Does the product need to integrate deeply with one chain environment or remain portable across several?
In practice, choosing a Web3 stack is less about finding the most advanced architecture and more about matching the architecture to the product’s real constraints. A consumer app, a DeFi protocol, an NFT platform and an enterprise-grade Web3 system may all use similar building blocks, but they should not assign the same weight to the same layers. The best stack is the one that makes the critical layer of the product stable, observable and economically sustainable from the beginning.
Common Architecture Mistakes in Web3 Systems
Most Web3 systems do not become fragile because the team chose the wrong tool first. They become fragile because responsibilities are assigned poorly across the stack. Architecture mistakes in Web3 are often expensive because writes are signed, reads often depend on indexing, finality is not the same as database confirmation and wallet behavior affects user trust directly. The earlier these mistakes are identified, the easier they are to correct before they turn into product-wide debt.
1. Treating the contract as the whole product
One of the most common mistakes is to treat the smart contract layer as if it were the entire application. Contracts are critical, but they are only one part of the stack. A working product still depends on wallet flows, orchestration, indexing, read models, storage choices and operational visibility.
This mistake usually leads to two problems. Either the contract becomes overloaded with logic that should remain elsewhere, or the rest of the system is left underdesigned because the team assumes the chain itself will solve product complexity. In practice, that usually creates slower releases, harder upgrades and avoidable support pain.
2. Mixing read paths and write paths
Reads and writes are not the same system and should not be designed as if they were. Reads depend on freshness, filtering, response time and queryability. Writes depend on signing, fees, nonce handling, confirmation tracking and finality. When both paths are forced through the same architecture, the result is usually brittle UX and unclear operational ownership.
This mistake often appears in products that read directly from raw chain state for customer-facing views while also trying to manage transaction lifecycle logic in the same flow. The better approach is to separate these paths early and treat them as different operational concerns.
3. Using raw RPC reads as the product read model
Direct RPC access is useful, but treating it as the customer-facing read model is a common mistake. Teams that do this often discover too late that the product cannot deliver consistent responsiveness or clear state under load.
In practice, the result is stale views, confusing user feedback and support issues that begin in the read path rather than in the contract layer.
4. Treating wallet UX like a standard login flow
A wallet is not just a login tool. It is part of the trust and signing boundary of the system. If the interface treats wallet interaction like a simple authentication step, the product will usually fail to explain approvals, fees, permissions, transaction consequences and confirmation states with enough clarity.
This mistake often shows up as abandoned signing flows, repeated retries, confused users and support tickets that look like product bugs but are really communication failures. Good wallet UX does not hide the system. It makes trust, action and consequence legible before the user commits.
On-Chain vs Off-Chain Decision Framework
One of the most important decisions in any Web3 product is deciding what belongs on-chain and what should remain off-chain. This boundary shapes trust, cost, upgradeability, user experience and operational recovery. Teams usually get better results when they treat this as a product architecture decision, not as a technical preference or an ideological choice.
The right question is not whether a feature can be placed on-chain. The real question is whether that feature benefits from public verification, shared execution and resistance to unilateral change. If it does, it may belong closer to the protocol. If it depends more on flexibility, recoverability, speed or operator control, it often belongs in off-chain services instead.
What should usually live on-chain
On-chain logic is best reserved for rules and state transitions that must be shared, verifiable and resistant to hidden modification. This typically includes ownership changes, transfer rules, protocol-level permissions, settlement-critical actions and any logic that needs to be enforced independently of one private backend.
What should usually remain off-chain
Off-chain services are often a better fit for workflows that need speed, iteration, support handling, flexible recovery and integration with traditional product systems. Notifications, search, analytics, orchestration, dashboards, customer messaging, reporting and many user-facing convenience features usually belong here.
The practical decision test
Before placing a feature on-chain, it helps to ask a small set of practical questions:
- Does this rule need public verification?
- Does it require shared execution across independent participants?
- Would hidden operator control weaken trust in the product?
- Is the logic stable enough to justify slower and more expensive change?
- Would failure here be unacceptable if it were only enforced off-chain?
If the answer to most of these questions is yes, the feature may belong on-chain. If the answer is mostly no, it is often better kept in off-chain application services, where the team can iterate faster and recover more easily.
Typical examples by architecture layer
On-Chain vs. Off-Chain Placement Guide
| Function | Recommended placement | Why |
|---|---|---|
| Ownership transfer | On-chain | Requires public verification and shared enforcement |
| Protocol permissions | On-chain | Should be transparent and resistant to silent change |
| Settlement-critical actions | On-chain | Must be deterministic and independently auditable |
| Search and filtering | Off-chain | Needs responsiveness and query-oriented data models |
| Notifications and alerts | Off-chain | Depends on orchestration and recoverable messaging flows |
| Analytics and dashboards | Off-chain | Usually depends on indexing, aggregation and queryable reads |
| Media storage and delivery | Off-chain or hybrid | Large assets usually require specialized storage and retrieval models |
| Audit-critical event history | Hybrid | Core facts may originate on-chain, while reporting and access patterns remain off-chain |
| Workflow orchestration | Off-chain | Needs flexibility, retries and operational control |
Common mistakes at the boundary
A frequent mistake is to move too much logic on-chain in the name of decentralization. This often creates unnecessary gas cost, slower iteration and harder upgrades without adding real trust value. The opposite mistake is just as dangerous: keeping trust-critical rules off-chain and expecting users to accept operator-controlled behavior where protocol enforcement would be more appropriate.
Think in terms of irreversibility and recoverability
A useful way to evaluate this boundary is to think in terms of what must be irreversible and what should remain recoverable. On-chain systems are better suited for actions that must produce durable, verifiable outcomes. Off-chain systems are better suited for actions that may require human support, process adjustment, retries or reversible operational handling. Once this boundary is clear, contract scope, read models, storage choices and release discipline become much easier to control.
Smart Contracts, Release Pipelines, and App Boundaries in Web3

What Protocol-Native Smart Contracts Actually Do in Production
Smart contracts are not just backend logic deployed to a blockchain. They are protocol-native programs that enforce shared rules, execute state transitions and record outcomes in a way that independent participants can verify. That makes them valuable when ownership, settlement, permissions and asset movement need to be enforced beyond the control of a single application server.
In a production Web3 system, this changes the operating model of the product itself. Multiple users, services and wallets can interact with the same protocol rules without depending on one private backend to define the truth. The result is not just a different implementation style. It is a different trust model for how state, authority and verification work across the system.
The practical implication is simple: contract logic should be treated as protocol infrastructure. It must be explicit, reviewable and resilient under public network conditions. Teams should design for deterministic behavior, clear state transitions and failure-aware interactions instead of assuming the chain will behave like a forgiving application backend.
WEB3 TERMINOLOGY
Protocol-Defined Modules
Protocol-defined modules are programs deployed to a blockchain that execute deterministically. Unlike standard software, they act as a shared system where multiple independent parties can interact with verified state changes. They enable trust-minimized ownership, settlement and permission control without relying on a single central operator.
Production-ready contract design begins with explicit assumptions. State transitions should be readable, edge cases should be reduced rather than deferred and wallet-facing behavior should remain aligned with protocol rules. Teams also need to account for real network conditions such as mempool congestion, fee volatility and confirmation delays, because those factors shape both user cost and product behavior long after code is deployed.
Why Execution Environments and Network Limits Matter
Every Web3 application runs inside an execution environment defined by the underlying chain. That environment determines how code is executed, how storage is priced, how transactions propagate and how confirmation and finality behave in practice. For Ethereum-compatible systems, that may include mainnet, testnet, devnet and local EVM environments. In other ecosystems, the same principle applies through their own runtime model.
This is why environment discipline matters. Development and staging environments should mirror the limits of the target chain as closely as possible, including gas constraints, block timing and realistic transaction behavior. If teams validate only under simplified assumptions, releases may look stable in testing and still fail under real network conditions.
It also helps to treat the execution layer as a constrained compute environment, not as unlimited infrastructure. The virtual machine defines how code is executed, stored and priced. Good teams write specifications early, validate runtime assumptions before deployment and make sure the product reflects the actual limits of the chain rather than an idealized version of it.
Recommended Web3 Release Workflow
A practical release workflow starts by isolating risky changes behind clear entry points. From there, teams validate behavior under realistic assumptions through local testing, staging and targeted debugging. Only then should they deploy progressively, moving from non-production environments to testnet and then to mainnet. In Web3, congestion, fee spikes and delayed confirmations are not rare edge cases. They are part of production reality and release planning should reflect that.
ARCHITECT’S NOTE: The costliest Web3 mistakes usually begin when protocol code is treated like ordinary backend code
In my experience, teams run into the most expensive failures when they assume smart contract releases can be handled with the same tolerance for rollback, silent hotfixes and hidden state corrections that exist in conventional backend systems. Public blockchain software does not give you that margin. Once state transitions become shared, signed and externally visible, release discipline becomes part of architecture. The pipeline is there to protect the product from irreversible mistakes, not just to make deployment look organized.
Defining the Boundary Between Core Protocol Logic and Off-Chain Services
By this point, the on-chain and off-chain boundary should already be clear. The operational question is what must remain irreversible under protocol rules and what can stay recoverable inside application services. Ownership changes, permission checks and settlement-critical actions usually belong near the protocol core, while search, notifications, orchestration and support flows usually remain off-chain, where they can evolve without weakening trusted rules.
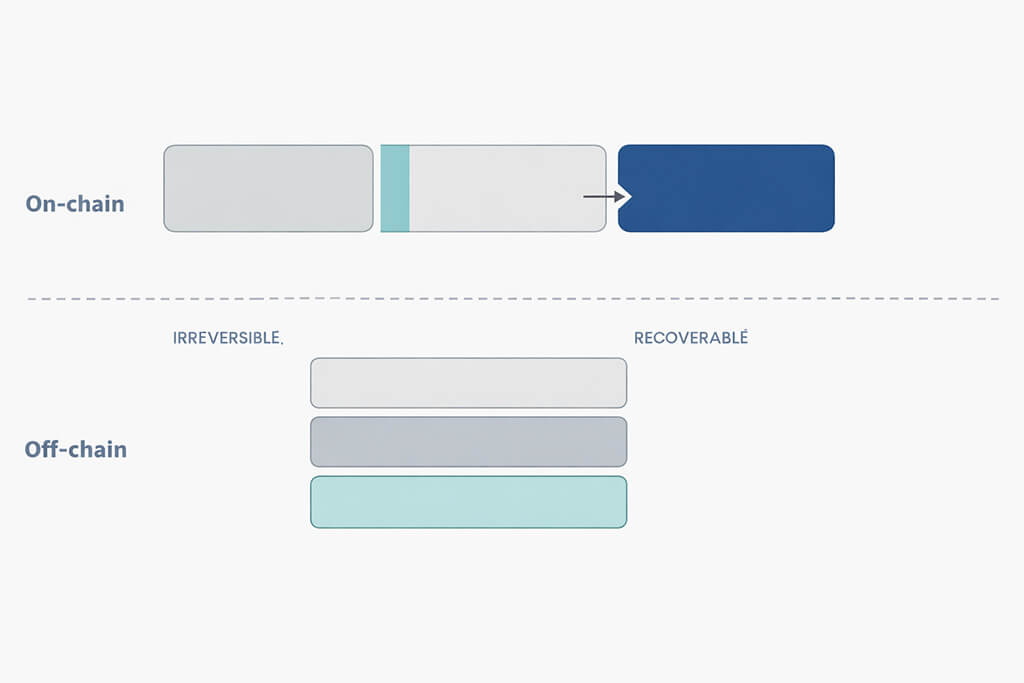
The diagram above translates that boundary into operational terms. Keep the protocol core narrow and irreversible. Keep user-facing workflows and recovery-heavy behavior in off-chain services, where teams can iterate without compromising the trusted layer.
That boundary also shapes the security model. In Ethereum, Solana and other public blockchain systems, every externally callable function should be designed as if malicious actors will reach it. Transactions may be reordered. External contract or oracle calls may fail or behave unexpectedly. Teams should review these assumptions before shipping any change that touches keys, permissions, settlement logic or user-critical flows. A written threat model and a structured review process make those decisions clearer and reduce surprises later in testing, support and incident response.
CRITICAL SECURITY ASSUMPTIONS FOR 2026
When defining the app boundary, developers should assume the environment is adversarial. Do not ship code without accounting for these baseline threats:
- Malicious Callers: Any function exposed to the network will eventually be called by bad actors.
- MEV & Reordering: Validators and block builders may reorder transactions for profit, so critical logic must remain order-independent.
- External Failure: Calls to other contracts, bridges or oracles may fail silently, revert unexpectedly or return unusable data.
Web3 Tech Stack Overview: Infrastructure, Decentralized Storage, and Scaling Considerations

Infrastructure choices in Web3 do not sit below the product as an implementation detail. They directly shape availability, latency, cost and user trust. Network access, read architecture, storage design, indexing strategy and observability all influence whether the product behaves predictably once real traffic and real transaction volume arrive.
This is why infrastructure planning should happen early. A Web3 stack is not operationally complete when the contract compiles or the UI connects to a wallet. It becomes production-ready only when the system can tolerate provider failures, separate reads from writes, deliver queryable data and make user-visible behavior traceable across layers.
RPC Access, Nodes, and Provider Reliability
Every Web3 application depends on reliable access to the network. In most systems, that access is provided through RPC endpoints used to read chain state, estimate transactions and submit signed writes. When that layer is fragile, the product fails quickly, even if the contracts and frontend are correct.
Relying on a single provider creates an avoidable failure domain. Rate limits, regional outages, degraded latency and provider-side incidents can all surface directly in the user experience. A resilient stack should use provider redundancy, health checks and failover rules from the beginning. In practice, provider SLAs, throttling behavior and endpoint quality belong in the architecture discussion, not in a post-launch incident review.
It also helps to treat read availability and write availability separately. A user may still be able to sign and submit a transaction while reads are stale or degraded. Designing that distinction clearly makes graceful degradation possible and prevents the entire product from collapsing behind one overloaded endpoint.
Designing Separate Paths for Reads and Writes
One of the most important design decisions in a scalable Web3 system is to separate read paths from write paths. They serve different purposes, fail in different ways and should not be optimized using the same assumptions.
Reads are usually best served from indexed, query-ready systems built for responsiveness and filtering. Writes are different. They involve signing, nonce handling, gas estimation, submission, confirmation tracking and finality uncertainty. Mixing both paths into one application flow creates brittle pipelines, inconsistent latency and confusing user expectations.
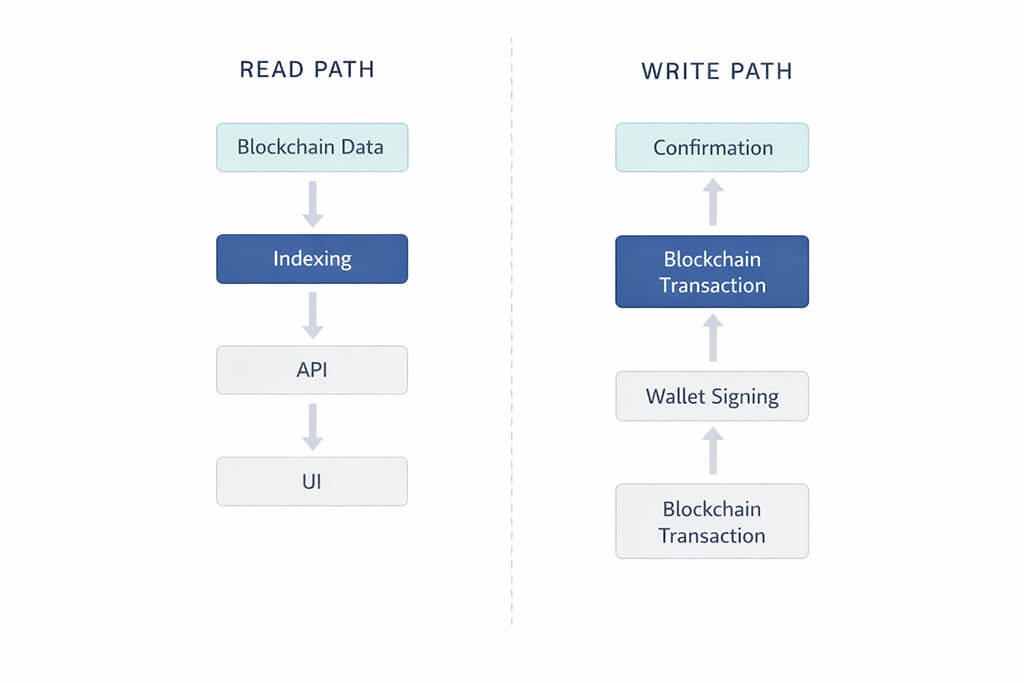
The diagram above illustrates the difference clearly. A read path typically starts with blockchain data, passes through indexing and APIs and ends in the UI as query-ready information. A write path starts with user intent, flows through wallet signing and transaction submission and only reaches a usable end state after confirmation. These are different systems and they should be designed, monitored and supported that way.
In my experience, teams tend to focus first on transaction correctness, signing and smart contract behavior. Those are essential, but the day-to-day product usually breaks elsewhere: stale reads, inconsistent indexing, weak caching strategy and unclear ownership of the query layer. In production, support pain often starts when users cannot see the right state at the right time, even though the chain itself is behaving correctly. That is why the read model deserves as much architectural discipline as the write model.
Operationally, the two paths should also be treated differently. Read-path failures need caching rules, freshness checks and retry strategies. Write-path failures need transaction-state handling, clear user feedback and careful privilege boundaries. When those concerns remain separate, the stack becomes easier to scale and far easier to debug.
Search Indexes, Databases, and Production Read Models
This layer becomes operationally important as soon as the product depends on searchable histories, filtered views, dashboards, notifications or audit-friendly reporting. At that point, the question is no longer whether indexed data is useful. The real question is how freshness, consistency and query performance will be managed in production.
A strong indexing plan should define how quickly data needs to appear in the product, which queries must stay fast under load and how lag or partial failure will be detected. In mature systems, these decisions shape support quality, product trust and incident clarity just as much as the contract logic does.
Every indexing strategy introduces tradeoffs between freshness, complexity, cost and observability. A narrow, well-defined plan reduces ambiguity across support, analytics and product logic. A vague one spreads that ambiguity everywhere.
Content-Addressed Data Storage and Permanence Tradeoffs
Not every asset belongs on-chain. Web3 products often need off-chain storage for media, documents, metadata and other large or frequently accessed files. The key decision is not whether to store these assets off-chain, but how to balance decentralized retrieval, permanence and cost.
IPFS and Arweave are often discussed together because they solve related but different problems. IPFS is useful when distribution, retrieval and caching matter most. Arweave is better suited to cases where long-term permanence is the primary goal. The right choice depends on the lifecycle of the asset, the retrieval expectations of the product and the cost model the team is prepared to maintain.
These storage choices also affect operations. Teams should know which assets are cacheable, which are pinned, which are expected to remain permanent and which can be replaced safely. Storage strategy is part of uptime planning, support planning and incident response, not only a cost decision.
Scalability, Performance, and User Experience Expectations
Scalability in Web3 is not only about throughput. It is about how well the product handles latency variance, fee volatility, delayed confirmations and degraded network conditions without confusing users or overwhelming operations.
That means teams should measure end-to-end latency, read freshness, wallet interaction time and confirmation distributions under realistic load. Congestion, fee spikes and variable confirmation timing are normal operating conditions on public chains. A production-ready stack anticipates those conditions and communicates them clearly instead of treating them as rare exceptions.
Performance budgets should be agreed during development. If the product depends on a certain read freshness window, confirmation time or acceptable retry pattern, those assumptions should be explicit before launch. Otherwise, scalability problems arrive first as UX problems, not as infrastructure metrics.
Observability, Monitoring, Operations, and Transactions
Every user-visible action in a Web3 product should be traceable across layers. That includes the initial UI interaction, the API request, the RPC call, the transaction submission, the confirmation state and the indexer update that eventually feeds the read model. When one of those stages fails, support and engineering teams need to know where the failure occurred and how it affected the user.
Observability should follow the user journey, not just the infrastructure chart. Logs, metrics and alerts are not optional extras in a Web3 platform. They are core operating components. Dashboards should connect technical symptoms such as RPC degradation, transaction backlog or indexer delay to the product outcomes users actually feel.
A strong operational model defines a small set of signals for each layer and keeps them tied to action. Frontend events should be logged. API behavior should be measured. RPC health should be monitored. Transaction failures should trigger alerts. Indexing lag should be visible. When those signals stay aligned, incident response becomes faster and product behavior becomes easier to trust.
Taken together, these infrastructure decisions define whether a Web3 product remains usable under real conditions. RPC access affects availability. Read and write separation affects reliability. Indexing affects queryability. Storage affects permanence. Scalability affects trust under load. Observability determines whether teams can understand and fix the system when reality arrives.
Conclusion: How to Build a Production-Ready Web3 Stack
In 2026, winning with Web3 is not about shipping the most features the fastest. It is about building a system that remains trustworthy and usable when latency rises, fees spike and demand becomes unpredictable. A strong Web3 stack is not a single framework, provider or SDK. It is an end-to-end system that connects trust, execution, data access and operations in a way the team can actually run in production.
The practical standard is straightforward. Every layer should have accountable ownership, a defined operating target and an explicit failure pattern. If you can explain what each layer is responsible for, how it can break and how success is measured, you can improve reliability without slowing delivery. That is the difference between treating blockchain integration as product engineering and treating it as a feature experiment.
That discipline also makes iteration safer. Start with explicit assumptions. Validate them locally. Test them in controlled environments. Then expand to broader network conditions only after the stack behaves predictably under realistic load, realistic latency and realistic operational constraints. In Web3, maturity does not come from adding more components. It comes from reducing ambiguity across the components you already have.
Final takeaways
- Treat the Web3 stack as a system of boundaries, not a bundle of tools
- Assign accountable ownership, operating targets and known failure patterns to every layer
- Separate query flows, transaction flows, runtime assumptions and operational recovery early
- Validate infrastructure, contract behavior and user flows under realistic conditions before scaling
- Design for observability, because production trust depends on visible system behavior
The best Web3 systems are not the most complicated. They are the ones that stay understandable, observable and resilient as real conditions arrive. Teams that design around accountable ownership, explicit failure patterns and operating targets usually ship faster and break less expensively.
Next in the series: Web3 marketing playbooks and community tools.
Web3 Stack Architecture, Smart Contracts, Infrastructure, and Scaling
This FAQ answers the most practical questions developers and product teams ask when planning a Web3 stack in 2026. It covers architecture layers, smart contracts, on-chain vs off-chain boundaries, read and write paths, storage, indexing, infrastructure reliability and production readiness.
Type to filter questions and answers. Use Topic to narrow the list.
Showing all 9
No matches
Try a different keyword, change the topic, or clear filters
-
A Web3 stack is a layered system for building blockchain-based applications in production. In practice, it includes the user interface, wallet flows, application services, smart contracts, execution environment, data indexing and developer tooling, all working together to support trust, execution, reads, writes and operations.
Key points- Defines the Web3 stack as a production architecture model
- Connects UI, contracts, runtime, data and tooling
- Sets up the rest of the article clearly
Learn more: The 6 Layers Of A Production Web3 Stack Opens in the same page.
Reference: Crypto, Web3 and Blockchain
-
The biggest change is where trust lives. In Web2, the backend usually acts as the main authority for identity, writes and state.
In Web3, trust is distributed across wallets, smart contracts and shared chain state, which means signing, confirmation, finality and read models all affect the product architecture directly.
Key points- Highlights the trust-boundary shift
- Explains why signing and finality matter in architecture
- Useful for readers comparing conventional and Web3 systems
Learn more: What Changes Compared To A Typical Web2 Blueprint Opens in the same page.
Reference: Crypto, Web3 and Blockchain
-
Features that need public verification, shared execution and resistance to unilateral change usually belong on-chain. Ownership changes, permission checks and settlement-critical logic are common examples.
Search, notifications, analytics, orchestration and many support or reporting workflows usually work better off-chain, where they remain faster, more flexible and easier to recover operationally.
Key points- Gives a practical placement rule
- Maps trust-critical logic to on-chain systems
- Maps recoverable product workflows to off-chain services
Learn more: On Chain Vs Off Chain Decision Framework Opens in the same page.
Reference: Smart Contracts Development
-
Reads and writes behave differently in Web3 and should not be optimized as if they were the same system. Reads usually depend on indexed, query-ready data built for speed and filtering.
Writes depend on signing, gas, nonce handling, transaction submission and confirmation uncertainty. Separating the two reduces support complexity and makes the stack easier to scale and operate.
Key points- Clarifies a core Web3 design principle
- Explains why indexed reads differ from transaction writes
- Strong FAQ target for architecture and scaling intent
Learn more: Designing Separate Paths For Reads And Writes Opens in the same page.
Reference: DevOps
-
Smart contracts are only one layer of the system. A production product still depends on wallet interaction, backend orchestration, runtime behavior, indexing, storage and observability.
Contracts enforce protocol rules and shared state transitions, but the product experience depends on how the surrounding layers handle reads, writes, failures and user-visible behavior.
Key points- Prevents readers from overfocusing on the contract layer
- Reinforces full-stack architecture thinking
- Links naturally to smart contract capability context
Learn more: What Protocol Native Smart Contracts Actually Do In Production Opens in the same page.
Reference: Crypto, Web3 and Blockchain
-
Raw blockchain data is rarely shaped for product use. Most production applications need searchable histories, dashboards, notifications, analytics and responsive user views that nodes do not serve directly.
Indexing turns blocks and logs into structured, query-ready data that the product can actually use at scale.
Key points- Explains why raw chain data is insufficient
- Supports search intent around indexers and read models
- Reinforces production-read architecture
Learn more: Layer 5 Data Indexing And Queryable Read Models Opens in the same page.
Reference: Ludo. Reputation platform of Web3
-
IPFS is generally the better fit when distribution, retrieval and caching matter most. Arweave is a stronger choice when long-term permanence is part of the product promise.
The right decision depends on the asset lifecycle, retrieval expectations and the storage cost model the team is prepared to support.
Key points- Answers a concrete storage comparison question
- Differentiates retrieval/distribution from permanence
- Good long-tail FAQ intent match
Learn more: Content Addressed Data Storage And Permanence Tradeoffs Opens in the same page.
Reference: Ludo. Reputation platform of Web3
-
A production-ready Web3 stack has clear layer boundaries, reliable infrastructure access, indexed read models, realistic runtime assumptions and operational visibility across the system. Each layer should have accountable ownership, explicit operating targets and known failure patterns so the team can scale safely and troubleshoot under real network conditions.
Key points- Strong concluding FAQ for high-intent readers
- Ties architecture to operations and reliability
- Good candidate for a featured FAQ answer
Learn more: Conclusion How To Build A Production Ready Web3 Stack Opens in the same page.
Reference: Crypto, Web3 and Blockchain
-
Teams should monitor the full user-visible path across the stack: UI events, API behavior, RPC health, transaction submission, confirmation states and indexing lag. Observability should follow the actual product journey so support and engineering can connect technical failures to what users experience.
Key points- Covers post-launch operational intent
- Connects monitoring to user experience
- Supports SRE/operations-oriented retrieval
Learn more: Observability Monitoring Operations And Transactions Opens in the same page.
Reference: DevOps
Glossary: Core Web3 Stack Terms for Developers 4
- Web3 Stack
- A Web3 stack is the full architecture used to build and operate a blockchain-based product in production. In this article, it includes the interface, wallet flows, application services, smart contracts, execution environment, data layer and developer tooling.
- Trust Boundary
- The trust boundary is the part of the system where authority, verification and control change hands. In Web3, that boundary shifts away from the backend alone and is shaped by wallets, contracts and shared chain state.
- Wallet
- A wallet connects identity, signing authority and asset control. It is the point where users authorize actions, approve transactions and interact with the blockchain through the product interface.
- Smart Contract
- A smart contract is a deterministic program deployed to a blockchain that enforces shared rules and records state transitions in a verifiable way. It is best used for ownership, permissions, settlement and other protocol-critical behavior.


